Nginx 1.7.8 is now available, and I’m really happy to see this entry in the changelog:
Feature: now the “tcp_nodelay” directive works with SPDY connections.
To be more specific, this commit.
The Story
Back in September I spun up a private instance of webpagetest ( WPT ). One of the first things I did was run near optimal condition tests. I wanted to see what the lower bound were for a few performance tests. The test system was very close to one of our data centers ( less than 1ms ping times ), so I configured tests to use Chrome as the browser, with no traffic shaping.
Like a kid with a new toy on Christmas morning I started running tests against this private WPT instance. Quickly something odd came up. In some cases we were seeing requests for very small ( sometimes less than 1kb ) resources take much longer than they should have. And by “much longer”, I mean these were 3 to 4 times slower than requests for larger resources.
Long story short, these slower small requests were seeing ~200ms delays in time to first byte ( TTFB ). But it only happened with SPDY, with compression enabled, for small files ( my tests showed 1,602 bytes or smaller ), when the small file was the first resource requested in the SPDY connection. Once I was able to list all of the variables that needed to be in place it was very simple to reproduce the problem using WPT.
Some of you will look at the mention of a ~200ms delay and immediately recognize this as a delayed ack issue:
When a Microsoft TCP stack receives a data packet, a 200-ms delay timer goes off. When an ACK is eventually sent, the delay timer is reset and will initiate another 200-ms delay when the next data packet is received.
( Note that the WPT tester system in our instance uses Windows, so that we can test Internet Explorer )
But that is why Nginx has a tcp_nodelay option. Unfortunately it wasn’t being applied when these variables came together in a SPDY connection. I started a thread in the WPT forums about this and we all basically agreed that this was the issue.
The systems team at Automattic reached out the Nginx team, describing what we were observing and how to reproduce it. They sent back a patch, which I ran through my tests and confirmed that it fixed the problem. The patch led to the commit I mentioned above. And now that change is part of the Nginx 1.7.8 release.
Waterfall
Here is what this looks like in action. First, a WPT waterfall graph using Nginx 1.7.7:
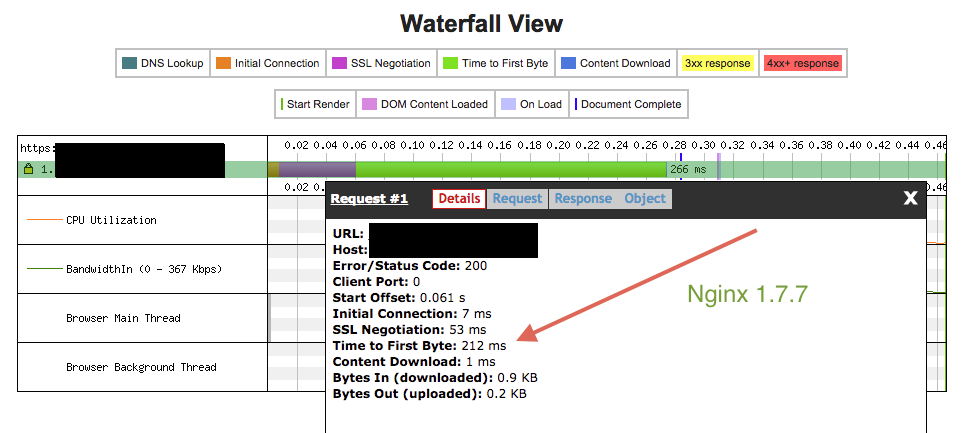
That TTFB of 212ms is significantly slower than it should be. Compare that with the same test conditions using Nginx 1.7.8:
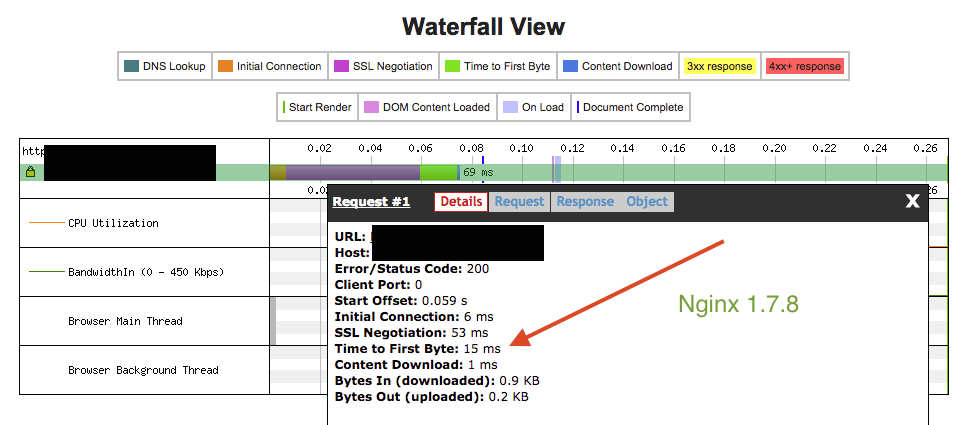
A TTFB of 15ms is inline with what I expected to see. Going from 212ms to 15ms is a 14x improvement! The total request time dropped from 266ms to 69ms, a 3.8X improvement. I’ll take gains like that anytime.
Reproducing This Yourself
I ran numerous tests during this process. To make running new tests easier I put together a simple script to take care of the Nginx build and configuration:
For each test I’d spin up a new DigitalOcean VM with Ubuntu 14.04 LTS. The build script would complete in a few minutes and then I’d run new WPT tests.
Conveniently it turns out that the default Welcome to nginx! page is small enough to trigger the ~200ms delay.
With all of that in place you can run a test at webpagetest.org to see this in action. I’ve been using the following test config:
– Test Location: Dulles, VA
– Browser: Chrome
– Connection: Native Connection ( No Traffic Shaping )
– “Ignore SSL Certificate Errors” ( under the Advanced tab ) — this is need because I’ve been using a self signed cert
The “Dulles, VA” location has a fast enough route to DigitalOcean “New York 3” that you can still observe the ~200ms TTFB difference between Nginx 1.7.7 and 1.7.8.
A big thank you to the Nginx team for fixing this.
9 replies on “Nginx 1.7.8 – Fixes 200ms Delay With SPDY”
Did you test 1.6.2 version if it has same delay problem ?
Thanks for sharing this =)
I don’t think that I ever tested Nginx 1.6.2. I was focused on recent versions.
[…] Now that we have seen why the components of TCP lets see how their interaction causes a deadlock.Instead of a contrived example to demonstrate this classic problem , lets take a look at this problem in the wild. The thread has a lot of details from WPT waterfalls to tcpdumps. The TLDR can be read here if you are impatient […]
I’m having the same problem as described in this article.
“It applies to all versions up to 1.7.8” unfortunately.
Reference: http://mailman.nginx.org/pipermail/nginx/2015-February/046651.html
Correct, you’ll need 1.7.8 or newer in order to fix that.
Thanks Joseph for your fast reply,
I have asked the Nginx developers to make a patch for Nginx 1.6.
This is a major loss of function and a critical bug, if you ask me,
because the existing 1.6. tcp_nodelay won’t work as it should be.
I don’t know what the Nginx back porting policy is ( or if they have one ). I agree that it would definitely be helpful for those still using the 1.6.x versions.
I forget to thank you for the article. So thank you for that.
Btw The Nginx team is going to evaluate the case, see:
“We will discuss merging this code to 1.6 for the next release but we
don’t have a schedule for 1.6.3 yet.” – Maxim Konovalov
Wow, thanks so much for writing this article! I finally got to put SPDY on a server, and noticed that the TTFB was actually pretty bad. After Googling for awhile I stumbled onto this. I was extremely skeptical that this was actually my problem. But I was using Nginx 1.6 so I figured I might as well upgrade to 1.7. As soon as I did, webpagetest started giving me As for TTFB. Crazy.
Thanks again!